
- ”GISTAPWO-666,” and “the program”
- Khazarian Mafia Gangstalking
- Organized Gang Stalking, Militant Judaism and Organized Crime
- Organized Gang Stalking, Jewish Mafia Psychotronic Warfare
- Jew World Order Homeland Security Touchless Torture Fusion Centers Synagogues
- Organized Gang Stalking, Militant Judaic Mafia Mind Control Artificial Intelligence
- Organized Gang Stalking Homeland Security Jews Militant Judaic Mafia Totalitarian Conspiracy
- Organized Gang Stalking Homeland Security Jews Militant Judaic Mafia
- AFI 100 Greatest Movies
- Airlines Toll-free
- AMTRAK Hompage
- American Medical Association: Doctor Finder
- Ancestry.com - "Search over 52 million names; look up by name the birth and death dates and Social Security numbers of the deceased."
- Annals of Improbable Research
- AT&T AnyWho Toll-Free Directory - comprehensive listing of 800 and 888 phone numbers.
- Anyday - Find out birthdays, death dates, and special events that happened any day of the year.
- Archives.com - "Trace your genealogy and family tree to learn more about your family's history."
- Area Code / Country Code Look-up
- Ask.com - site allows you to enter plain English questions, to which Jeeves serves up suggested web pages.
- ATM Locator: AMEX | MasterCard | VISA
- Atlapedia Online
- Atomic Clock
- Autolist - 'Looking for the best site to find a used car? Browse millions of used car deals everyday with our free search engine. Find your dream car now!'
- BabyNames.com - "BabyNames.com has been the the #1 site for names and naming since 1996."
- Bank Rate Monitor
- Bartlett's Familiar Quotations - passages, phrases and proverbs traced to their sources.
- Best Doctors - worldwide healthcare services
- Better Homes & Gardens Home Improvement Encyclopedia
- Big Fare Cut Index
- Biography.com - "Read biographies, play games, watch interviews and video clips at Biography.com. Check out our Born On This Day, Deathiversary, and Black History sections. Visit The Biography Channel for great TV shows like BIOGRAPHY, Notorious, I Survived..., and more."
- BookWire - the first place to look for book information
- Books On-line - "Listing over 35,000 free books on the Web."
- Browser Watch - "Web browser news for Internet Explorer, Google Chrome, Mozilla Firefox, Opera, and Apple's Safari web browsers."
- Calendar: Perpetual
- CDC Travel Information - Health-related travel advisories, vaccine recommendations, and much more.
- Census Bureau Quick Facts
- Census Bureau Index A-Z
- CIA World Factbook - current data on every country in the world.
- ClassMates - Search for people you went to high school with. Add yourself to the database--if you want to be found.
- Company Profiles - information on over 45,000 leading public and private companies in the U.S.
- Complete Home Medical Guide - 3rd Edition, 1995
- Constitutions, Statutes & Codes (including the full US Code)
- Consulates and Embassies
- Consumer Price Index
- Consumer Reports Online
- Contacting the Congress - comprehensive contact information for members and committees of the U.S. Congress.
- Conversion Online - Excellent site to convert anything to anything.
- Convert-me.com - interactive calculators for many measurement systems both commonly used like metric and U.S. Avoirdupois and quite exotic like Ancient Greek and Roman. U.S. to metric conversion is now easy and fast!
- Country Studies/Area Handbook - Library of Congress - online series presently contains studies of 85 countries
- Countries of the World - InfoPlease
- Currency Converter - View any exchange rates among the 164 currencies both current and historical.
- Date and Time Gateway
- Driving Directions: Mapquest
- Earth Calendar - The Earth Calendar is a daybook of holidays and celebrations around the world.
- Earthquake Information from the USGS - daily and weekly quake reports, geophysical information on earthquakes, and other background information.
- EconData - comprehensive resource for U.S. socioeconomic data on the net
- EDGAR Database of Corporate Information - EDGAR (Electronic Data Gathering Analysis And Retrieval) is a service of the United States Securities Exchange Commission (SEC)
- Elements of Style - William Strunk's classic on proper English usage
- Ethnologue - Languages of the World
- Facts Encyclopedia: Refdesk - 7,500+ Sites - 73 Subjects
- FedEx Shipping & Logistics - FedEx.com is your single source fo time-sensitive, time-definite and day-definite package, envelope and freight transportation services both domestic and international.
- FedNet
- Fedstats: One Stop Shopping Federal Statistics - Statistics and information from more than 100 federal agencies.
- FindLaw - Excellent one-stop source for legal information
- Flags of all Countries
- Flags of the World
- Fodors - 'Your smart choice for travel."
- Free Internet Encyclopedia
- Frequently Occurring Surnames in America - from the Census Bureau
- Fundamental Physical Constants
- Games: Yahoo - "Free online and downloadable games! Play arcade games, board games, card games, puzzle games and other free games at Yahoo! Games."
- Geologic Time
- Geostationary Satellite Server - Real-time satellite images provide a view from above.
- Grant Writing Guides - "Need grant funds? This site offers a 10-Point Grant Writing Guide designed to help you win grant funds for your organization."
- Guide to Airport Rental Cars
- Harper's Index - Statistics that may surprise you.
- Healthfinder - "Your source for reliable health information from the Federal government. Offering quick guides to healthy living, personalized health advice, and tips and tools to help you and those you care about stay healthy."
- Homework Helper: Refdesk - Homework help for K through college
- Hoover's Online - information on more than 10,000 of the largest public and private companies in the US and around the world.
- How Far Is It?
- Human Anatomy Online - over one hundred illustrations of the human body with animations and thousands of descriptive links.
- Images - Yahoo!
- Information Please - from the print reference database, offering millions of useful and interesting facts on a wide range of topics online. Also includes a dictionary and encyclopedia.
- International Data Base - is a computerized data bank containing statistical tables of demographic, and socio-economic data for all countries of the world.
- International Directories - International inquiry names, addresses, telephones and faxes.
- International Marine Signal Flags - reference site that explains the signal flags and the semiphore flag waving system
- International Telephone Directories - Find anyone anywhere in the world. All the white and yellow pages telephone directories available on the web.
- International White and Yellow Pages - a collection of phone directories from around the world.
- Internet 800 Directory - - free listing of toll-free numbers. Companies are listed by category, company name, state, and 800 number.
- Internet Movie Database
- Internet Public Library
- iTools! - Internet Tools
- Jane's Information Group - weaponry catalogues.
- JudysHighHeels.com: Inspiration with Style - "An inspirational website for Women to Embrace, Empower, Inspire and Enjoy - Women Connecting Women with High Heels!"
- Kelley Blue Book - new and used car pricing
- Largest Known Primes
- LegalDocs - Do your own legal papers
- Library of Congress Home Page
- Martindale's Reference Desk
- MapQuest!
- Mayo Clinic - "More than 3,300 physicians, scientists and researchers from Mayo Clinic share their expertise to empower you to manage your health."
- MedicineNet
- Mensa Home Page, The
- Merck Manual
- MetaCrawler
- netLibrary - "The World's Largest Collection of Electronic Books"
- New York Times Books - includes the complete Sunday Book Review, daily book related news and reviews, a searchable archive of over 50,000 New York Times Book Reviews, and more.
- Nobel Prizes - Comprehensive historical list of winners in all categories.
- Occupational Outlook Handbook - reference tool used to research job information and trends
- Old Farmer's Almanac
- Online Calculator
- Medical Dictionary: MedlinePlus
- OneLook Dictionaries - 13,587,880 words in 1024 dictionaries indexed.
- Passport Services - U.S. State Department.
- Perry-Castaneda Library Map Collection
- Periodic Table - WebElements
- Perseus Project, The - "Detailed searchable library of texts, translations, art and archaeology of Ancient Greece and Rome."
- Peterson's Guide to Colleges - information on undergraduate and graduate education in the US
- PollingReport.com
- Project Gutenberg - "Project Gutenberg offers over 60,000 free ebooks to download."
- PubMed - "Provides free access to Medline."
- Pew Research Center: 18 striking findings from 2018 - Pew Research Center takes the pulse of Americans and people around the world on a host of issues every year. They explore public opinion on topics ranging from foreign policy to cyberbullying, as well as demographic trends, such as the emergence of the post-Millennial generation and changes in the number of unauthorized immigrants in the United States. Here are 18 of this year's standout findings, taken from their analyses over the past year.
- Public School Review - "Profiles, statistics and reviews of over 100,000 public schools in the USA. Help with finding the right school."
- Pulitzer Prize Web Site
- Purdue Univ. Online Writing Lab - over 100 handouts available on all aspects of writing correctly
- Reference Shelfs on the Net: Refdesk
- Reverse Lookup - "AnyWho is a free directory service with residential, business, and government white and yellow page listings."
- Roget's Internet Thesaurus - Find words relating in six main classes.
- Rulers - Large listing of heads of state.
- RxList -"Medications and prescription drug information for consumers and medical health professionals. The most popular drugs and their side effects, interactions, and use."
- Search Engines: Refdesk - 260 search engines in 19 categories
- Search Systems - "Free Public Records Directory at SearchSystems.net. The Internet;s largest directory of free public records databases. Search for criminal records, judgments, tax liens, bankruptcies, find people, reverse phone, background checks, search, licenses"
- Semaphore Flag Signalling System
- Shakespeare - The Complete Works
- Smoking Gun, The - "The Smoking Gun brings you exclusive documents--cool, confidential, quirky--that can't be found elsewhere on the Web. Using material obtained from government and law enforcement sources, via Freedom of Information requests, and from court files nationwide, we guarantee everything here is 100% authentic."
- Social Security Death Master File (fee-based)
- State and Local Government on the Net - guide to government sponsored sites.
- Statistical Abstract of the United States - one-stop source for statistical information about the U.S.
- Sunrise/Sunset Computation - Type in a city name and find out times for sunrise, sunset, and more
- SwitchBoard - "Find any person or business listed in the phone book."
- Ticketmaster
- Thomas: Legislative Information on the Internet
- Today in History: New York Times
- Tucows - "The original software download site, Tucows hosts more than 40,000 virus and spyware free software titles."
- Ultimate E-mail Directory, The
- Ultimate White Pages, The
- Ultimate Yellow Pages, The
- United Parcel Service - Track any UPS bar coded package - any time, any where in the world.
- Unit Conversions
- USGenWeb Project, The - genealogy information for each county in the United States. Organized by state.
- U.S. National Debt Clock
- U.S. Population Clock
- U.S. Postal Service - "Fully featured online version of your local post office."
- U.S. Postal Service Address Quality and Zip Code Lookup
- Virtual Body, The
- Visible Human Project - creating a complete, anatomically detailed, three-dimensional representations of the male and female human body.
- WWW Virtual Library - extentive library on hundreds of subjects
- Webster's Dictionary - the on-line version of Merriam-Webster's Collegiate Dictionary, Tenth Edition
- Weights & Measures
- WhatIs - "An a-z database of all things computers."
- White House, The
- WhitePages.com - a global directory and index of e-mail addresses and phone numbers.
- Who Represents You in Congress? - Project Vote Smart
- WhoWhere - find email addresses, phone numbers, and addresses, etc.
- Why Files: Science behind the news
- World Clock - Current local times around the world
- World's Most Wanted Criminals
- WorldPages - more than 112 million integrated white and yellow page listings
- World Population Clock
- World Resources Institute
- Worldwide Yellow Pages
- World Time Zones
- Yellow Pages
- Zip2 - search for over 16 million businesses
- ZIP Code Lookup - USA
Best 153 Uncensored Unfiltered Private Metasearch Crawler Engines ~ Best Uncensored Search Engines 2022
Anti-Mind Control Anti-Thought Control Anti-Brainwashing Most Uncensored Web Browser Uncensored Image Search Uncensored Video Search Most Unblocked Search Engines Search Tutorial

Yandex.com Qwant.com Rambler.ru Aloha PreSearch Startpage.com Search.meta.ua Parseek.ir Mail.ru Ecosia Qmamu Luxxle AOL Search Searx
Kvasir.no Excite uSearch Brave Ahmia .onion You.com Fireball Metabear.ru Atlas Centrum
WebCrawler Lycos Ekoru Info Search Encrypt Swiss Cows AI Discreet Search Oscobo Web.de Wayback InfinitySearch Monstercrawler
Uncensored, Unfiltered, Unblocked Search Engines, Notable or Found Useful
Wow OneSearch Sputnik Metacrawler
Petal Qmamu
Alternative Uncensored Search Engines Tutorial
There are 100 largely uncensored, unfiltered, unblocked alternatives to Google, Bing, Yahoo and Ask above. The following Search Engines seem to be, circa 2022, the most uncensored, unblocked of all "uncensored" Search Engines: Yandex.com, Rambler.ru, Startpage.com, Search.meta.ua, Parseek.ir, Mail.ru, Kvasir.no, Boomle.ru, Cluuz.com, Fireball.com, Metabear.ru and DuckDuckgo.com. What is uncensored, unfiltered in a Russian Search Engine is what is often censored in the West, and vice versa. While initially researching U.S. Government Black Projects and Operations, in some search instances nearly every link on this page was followed. Sometimes, Yandex Advanced, Yahoo Advanced, Google Advanced and WebArchive.org were helpful. So was using the Tor Browser and utilizing Torch Uncensored Unfiltered Unblocked Search Engine, etc.
This page was made in large part by using alternative uncensored search engines to search for more alternative, uncensored, unfiltered search engines. Near the top of the page are links to 13 hassle-free Image Search Engines: Yandex Images, Bing Images, ImageAtlas, AOL Images, Yahoo Images, UnBubble Images, PicSearch, Zapmeta Images, Mail.ru Images, Boomle Images, Rambler Images and DuckDuckGo Images.
As of July 15, 2022 there are no broken links and few to no spam ads that we are aware of on the roughly 100 search engine pages – no preponderance of “parked domain” pages like you see on many other similar search engine pages.
Many people do not want Multinational Corporations, Governments, etc., tracking and recording their every nuance. On any given day, I use 6-15 (some days even more) of the links on this page; mostly to track how bad Censorship has become. If you use TV, the car radio and one major Search Engine to get news and info, you are in the dark, literally in a blacklist or a "whitelist" sanitized, propaganda effervescence balloon.
Go to parseek.ir and search for news topics you know are censored, U.S. Government Black Operations, etc. Try going to parseek.ir and search for "U.S. Government Black Operations whale.to" or "U.S. Government Black Operations bibliotecapleyades.net" (without quotes). It is all about pattern matching.
If you were to encounter (extremely rare, but still...) a "takeover" ransom page… on a Mac, type command-option-escape. Quit the broswer in the small processes window. On a PC, type control-alt-delete, then quit the browser in the processes window. Reboot to refresh RAM.
If you are looking for “dark news”, bear in mind the DHS / NSA blocks everything it possibly can. At the risk of sounding paranoid, one of the foreign, highly alternative search engines coughed up about ten pages of results not available in the big four search engines. The following day, its results were just like the big four – literally everything worth reading in the results disappeared overnight. Who do you think has the power to re-arrange “the open Internet” or “overhaul a foreign search engine” overnight?
It is highly recommended you use the search engines with JavaScript off, pop-up windows blocked and up to date antivirus protection – just in case. All but 5 links open in Firefox and IE, those 5 .onion URL's open only in Tor browser bundle.
If you have not done so, download, install and use Yacy (pronounced Ya see) peer-to-peer search engine. Much of the info in the Fukushima Plumegate articles came from Yacy searches.
This is not a comprehensive list of all search engines, but rather a one-page list of foreign, clustering, deep web and alternative uncensored search engines.
Search Engine Boolean crash course: "targeted individual" or "organized harassment" and +Morgellons … Try it with and without "quotes" and use minus signs on propaganda disinfo words. If you don't find any results, use less verbage, like "targeted individuals Morgellons" (no quotes). The German metasearch engine Fireball.com boasts the ability to handle far more keywords than google, bing, yahoo and ask. Fireball.com also boasts the ability to handle the most minus-sign words (keywords you wish excluded from results). There are many system trade-offs in 100 search engines, but the ability to add 10 keywords and an additional 10 minus-sign words in Metager makes it my personal favorite at this time. I still have Google as my default homepage, but have several alternatives in my bookmarks for quick reference use. When all else fails, search for what you know or want and use an asterisk * as a Wild Card, for instance: my favorite rock band and * collaboration. Or Morgellons and *. Boolean works well with Swisscows.com (AI). But the powers that be have all of us mostly seeing a flea on a camel's ass through backwards binoculars.
On March 14, 2018, the link immediately above gave me the first 7 results as being "newsworthy". No spam, no obvious lies, etc.
Do diligent research, so you learn that "Security Role Players Morgellons" (no quotes) means the same thing, essentially. Some Search Engines do not handle plus and minus signs, quote marks, etc. Some alternative search engines handle 12 words, others balk at 6-7 words (or even less like 5). Sometimes less is more, no quotes, no Booleans: organized harassment Morgellons … just the three words, for example. The best search engines interpret -aliens as skip all content that has the propaganda, disinformation word "aliens"; you wish to filter out all "aliens" blather. Hence: "targeted individuals Morgellons -aliens" will work in the best 20-30% of the search engines list above. If the minus sign filter (-aliens) does not work, switch to another search engine, like sogou.com, Yandex.ru, baidu.com or mail.ru (or many, many others, above). Sometimes just thinking box out of the results in searching Swisscows.com for bitchute articles... ...Or search Rambler for Lissa's Humane Life...
When in doubt, don't use plus and minus signs, just use 3-5 appropriate words. When in doubt, use less words, generally. Now some contradicitions. The search "organized harassment +Morgellons -time -travel -aliens" means I wish for all results to include "Morgellons" and wish to block out "time travel aliens"… Different words, similar example. "global warming +coral +bleaching -hoax" will give you the Liberal's pages. "Global warming +hoax" will give you the Republican's pages. Or just use Google advanced (with no plus or minus symbols, it automatically includes them) - anything that gets you using Booleans and filters (minus signs) is to your search engine advantage.
Two minus signs are a plus in many search engines. A plus-minus (i.e., +-aliens) is a minus. Learn to think of "and" or "or" or both, when appropriate. "Targeted and individuals or organized and harassment or srp's -aliens". If you get zero results, try less words or drop "-aliens"; or better yet, use a more sophisticated search portal. If time permits, try one of your same exact searches in all 153 search engines to compare. That was how the article, "Mossadgate, NSA Prism" was in large part researched… Google has a Boolean help page well worth your time that deals with Search Engine Boolean beyond the scope of our short lesson…
For blacklisted news, the first 15 Search Engines links top above and the entire page is what it takes to not live in an absence of "Blacklisted News" Government/Media/Multinationals Propaganda Bubble, totally. Please don't get the impression to totally boycott the Big 5. Notice the links to Google Advanced, Yahoo Advanced and Yandex Advanced (above); three extremely powerful tools.
Let's review using Boolean to make Internet Search more uncensored and unfiltered using our Boolean unfiltered:
surveillance role players +gangstalkers targeted individuals +fbi +cops +cointelpro -aliens -reptilians -nibiru
Click the text above to see how very uncensored Fireball.com handles Boolean. The Internet is both censored and very easy to uncensor. Now click the same Boolean, imediately below, to see how Parseek handles the Boolean:
surveillance+role+players gangstalkers+targeted+individuals fbi cops cointelpro+-aliens+-reptilians+-nibiru
Try one more unfiltered, uncensored, unblocked web searches with the same terms on Yandex.com:
surveillance role players +gangstalkers targeted individuals +fbi +cops +cointelpro -aliens -reptilians -nibiru
Of the three search links above, which do you think gave the most uncensored, unfiltered, unblocked results?
Try using Yandex, Mozbot.fr and Kvasir.no. We trust you are now search engine proficient. Be sure to try the Cluuz and Search.meta.ua Search Engines, two of our favorites for general or specialized web surfing… Experiment, it is how we learn.
Alternative search engines are well worth using and generally safe to use. Much of the news found is more interesting than that found in mainstream search engines, that by comparison seem censored. Hence, uncensored unfiltered unblocked search, Deep iInternet Deep Web, Hidden Internet are the themes of this page. Foreign National and Independent Search Engines that don't track you with cookies for unblocked, unfiltered and uncensored searches. More than a dozen image search engines for unblocked, unfiltered, uncensored image searches. For Dark Web info, read articles below.
The short list at the top of the page are the most unblocked, unfiltered, uncensored Search Engines: Yandex.com, Rambler.ru, Startpage.com, Search.meta.ua, Parseek.ir, Mail.ru, Kvasir.no, Boomle.ru, Cluuz.com, Fireball.com, Metabear.ru, DuckDuckgo.com and Gibiru. The Russians, Ukrainians and Iranians seem to have no interest in helping the NSA serve up an effervescent, censored Internet; or the machines work by uncensored, unfiltered by meta-proxy and anonymously, or both. We live in an era where AI is being touted as "society's savior/invest now" and AI is being simultaneously rolled out as an Orwellian propaganda/censorship tool.
Everybody knows the Internet is rigged; the Web Cognitive Disonnance is seeing your wife's spending habits all over newsgroups, "alternative" Jewish News sites, etc. Every bit and byte is rigged with commercialism's shadow splashed everywhere one turns to online. Each time one's brain synapses a fleeting interest in a subject, the NSA, DHS, FBI, Apple, Intel, Google, Amazon, FB, Twitter, airforce.mil, navy.mil, army.mil, et al file away one's very keystrokes to see if said taped keys can be used against one in some adversarial, profitable, or archival of "one's privacy" recording. Spy, profit, spy, profit. How long after we die do they keep our digital footsteps?
Two of the Search Engines that I felt were most anonymous search (did not data harvest on you) were Seznam.cz and Cluuz.com. The powers that be seem to starve such enities in the so-called "Search Engines" (URL-Erasers/Thought-Control-Portals). They almost got Metager.org, or partially or wholly Zionized it. Basically, we are witnessing the Zionization of "the free, open Internet". Note that what is left of Metager will handle a search string such as: Zionists+Zersetzung+Mind+Control+Matrix+Surveillance+Role+Players+Office+of+Naval+Intelligence+-aliens+-planet+-niburu and they don't appear totally Zionized.
Every time that you believe you have exhausted your boolean search engine skills, put out some effort and teach yourself how each search engine behaves to certain input:
How does Yandex react when you put a quoted phrase in twice, for example: +Gangstalking FirstNet Police Firefighters AT&T FirstNet +Gangstalkers?
How does Metager react when you put a quoted phrase in twice, for example: Gangstalking FirstNet Police Firefighters AT&T FirstNet +Gangstalkers?
How does Metacrawler compare to the Yandex and Metager when you look at the results, for example: police firefighters firstnet gangstalking gangstalkers zersetzung?
Summary
So, maybe you have been Googling "Jew Gangstalkers" and Google has given you the same articles, over and over.
Going to Yandex or Parseek and searching for "Jew Gangstalkers" will frequently yield the same dozen articles you saw at Google (or Bing). But click the search terms below and you will find that there are indeed new articles by new authors that you completely missed before now:
How many new searches can you make, mixing and matching the words above? Which Search Engines seem the most uncensored to you?
The hundred thousand dollar question is why do you need an Anonymous Search Engine and Unrestricted (Text or Image) Search? For journalists doing anonymous, unrestricted text searches, Yandex.ru, Parseek.ir, Startpage.com and DuckDuckgo.com, accessed from a Browser such as Tor are about as good as it gets. For journalists and most other people, browsing images in the Images section of this page should be sufficient for most purposes. This paragraph excludes perverts.
For those who wholeheartedly wish to break the law, you do realize the DHS/NSA/FBI are watching your every keystroke, in real time, as you read these words? Every single search term you have typed has been logged in IP logs - every embarrassing, frightful thing you typed is embedded in your remote history, in IP logs. This paragraph includes perverts.


QUICK REFERENCE / RESEARCH
Sat, Jan 1, 2022
.
|
|
Deep Web Research Tools

Semantic Search Tools and Databases
Meta-Search Engines
General Search Engines and Databases
Academic Search Engines and Databases
Scientific Search Engines and Databases
Custom Search Engines
Collaborative Information and Databases
Hints and Strategies
Helpful Articles and Resources for Deep Searching
International Handbook of Internet Research
International Handbook of Internet Research

The International Handbook of Internet Research

The Internet Research Handbook: A Practical Guide for ...

Internet Communication and Qualitative Research: A ...

Research Handbook on Governance of the Internet

Research Handbook on Governance of the Internet
Research Handbook on EU Internet Law: - Page 37

The Oxford Handbook of Internet Studies

The Extreme Searcher's Guide to Web Search Engines: A ...

Metacrawlers and Metasearch Engines
Unlike search engines, metacrawlers don't crawl the web themselves to build listings. Instead, they allow searches to be sent to several search engines all at once. The results are then blended together onto one page. Below are some of the major metacrawlers. Also see the Search Toolbars & Utilities page for metacrawler-style software that you can run from your desktop.
Award WinnersDogpilehttp://www.dogpile.com Popular metasearch site owned by InfoSpace that sends a search to a customizable list of search engines, directories and specialty search sites, then displays results from each search engine individually. Winner of Best Meta Search Engine award from Search Engine Watch for 2003. (Review: Dogpile Sports a Fetching New Look, SearchDay, Sept. 2, 2003. Updates: Dogpile Enhances Search Results Search Engine Watch Blog, Nov. 10, 2004 - Dogpile Adds New Features Search Engine Watch Blog, Jan. 18, 2005 ) Vivisimo http://vivisimo.com/ Enter a search term, and Vivismo will not only pull back matching responses from major search engines but also automatically organize the pages into categories. Slick and easy to use. Vivisimo won second place for Best Meta Search Engine in the 2003 Search Engine Watch awards and winner in 2002. (Review: Power Searching with Vivisimo, SearchDay, July 8, 2003) Kartoo http://www.kartoo.com If you like the idea of seeing your web results visually, this meta search site shows the results with sites being interconnected by keywords. Honorable mention for Best Meta Search Engine award from Search Engine Watch in 2002. Mamma http://www.mamma.com Founded in 1996, Mamma.com is one of the oldest meta search engines on the web. Mamma searches against a variety of major crawlers, directories and specialty search sites. The service also provides a paid listings option for advertisers, Mamma Classifieds. Mamma was an honorable mention for Best Meta Search Engine in the 2003 Search Engine Watch awards. SurfWax http://www.surfwax.com Searches against major engines or provides those who open free accounts the ability to chose from a list of hundreds. Using the "SiteSnaps" feature, you can preview any page in the results and see where your terms appear in the document. Allows results or documents to be saved for future use. Honorable mention for Best Meta Search Engine award from Search Engine Watch in 2002. Other Top ChoicesClustyhttp://www.clusty.com Clusty, from Vivisimo, presents both standard web search results and Vivisimo's dynamic clusters that automatically categorize results. Clusty allows you to use Vivisimo's dynamic clustering technology on ten different types of web content including material from the web, image, weblog and shopping databases. You can access each type of search by simply clicking a tab directly above the search box. (Review: Reducing Information Overkill, SearchDay, Sept. 30, 2004). CurryGuide http://web.curryguide.com/ Meta search engine for the US and several European countries, as well as in various subject areas. Has ability to save your results for easy rerunning at a future point. Excite http://www.excite.com Formerly a crawled-based search engine, Excite was acquired by InfoSpace in 2002 and uses the same underlying technology as the other InfoSpace meta search engines, but maintains its own portal features. Fazzle http://www.fazzle.com/ Fazzle offers a highly flexible and customizable interface to a wide variety of information sources, ranging from general web results to specialized search resources in a number of subject specific categories. Formerly called SearchOnline. Gimenei http://gimenei.com/ Gimenei queries an undisclosed number of search engines and removes duplicates from results. Its most useful feature is an advanced search form that allows you to limit your search to a specific country. IceRocket http://www.icerocket.com/ Meta search engine with thumbnail displays. The Quick View display, similar to what WiseNut has long offered, is cool. The service queries WiseNut, Yahoo, Teoma and then somewhat repetitively also includes Yahoo-powered MSN, AltaVista and AllTheWeb. Disclosure of search sources within the actual search results is not done, sadly. Makes it hard to know exactly where the results are coming from. Info.com http://www.info.com Info.com provides results from 14 search engines and pay-per-click directories, including Google, Ask Jeeves, Yahoo, Kanoodle, LookSmart, About, Overture and Open Directory. Also offers shopping, news, eBay, audio and video search, as well as a number of other interesting features. (Review: New Metasearch Engine: Info.com Search Engine Watch Blog, Oct. 18, 2004) InfoGrid http://www.infogrid.com In a compact format, InfoGrid provides direct links to major search sites and topical web sites in different categories. Meta search and news searching is also offered. Infonetware RealTerm Search http://www.infonetware.com This site is primarily designed to demonstrate classification technology from Infogistics. It's a meta search engine, and it does topical classification of results, like Vivisimo. However, it is unique in that you can select several different topics, then "drill down" to see results from all of them, rather than being restricted to the results from only one topic. Ixquick http://www.ixquick.com/ Meta search engine that ranks results based on the number of "top 10" rankings a site receives from the various search engines. iZito http://www.izito.com iZito is a meta search engine with a clever feature. Click on any listing you are interested in using the P icon next to the listing title. That "parks" the listing into your to do list. Click on the P tab, and you can see all the pages you've culled. It's an easy, handy way to make a custom result set. Also interesting is the ability to show listings in up to three columns across the screen, letting you see more results at once. (Review: iZito & Ujiko: Meta Search With Personality Search Engine Watch Blog, Sept. 29, 2004) Jux2 http://www.jux2.com/ This search result comparison tool is cool. It allows you to search two major search engines at the same time, then see results that are found on both first, followed by results found on only one of them next. The small overlap visual tool displayed is great. I used to make examples like this to explain search engine overlap and why one search engine may not cover everything. Now I have an easy dynamic way to do this. The stats link at the bottom of the home page provides more visuals. (Update: Jux2 Adds New Features, Search Engine Watch Blog, Oct. 13, 2004) Meceoo http://www.meceoo.com/ Meta search with the ability to create an "exclusion list" to block pages from particular web sites being included. For example, want to meta search only against .org sites? French version also offered. MetaCrawler http://www.metacrawler.com One of the oldest meta search services, MetaCrawler began in July 1995 at the University of Washington. MetaCrawler was purchased by InfoSpace, an online content provider, in Feb. 97. MetaEureka http://www.metaeureka.com Search against several major search engines and paid listings services. Offers a nice option to see Alexa info about pages that are listed. ProFusion http://www.profusion.com Brings back listings from several major search engines as well as "Invisible Web" resources. Formerly based at the University of Kansas, the site was purchased by search company Intelliseek in April 2000. Query Server http://www.queryserver.com/web.htm Search against major web-wide search engines, as well as major news, health, money and government search services. Turbo10 http://turbo10.com Turbo10 is a metasearch Engine accesses both traditional web search engines and some invisible web databases, with a very speedy interface. (Review: Make way for the contender to Google's crown, The Register, May 30, 2003) Search.com http://www.search.com Search.com is a meta search engine operated by CNET. It offers both web-wide search and a wide variety of specialty search options. Search.com absorbed SavvySearch in October 1999. SavvySearch was one of the older metasearch services, around since May 1995 and formerly based at Colorado State University. Ujiko http://www.ujiko.com/ From the makers of visual meta search tool KartOO, this is a really slick service to try. Do your search, then scroll through the list. See something bad? Click the trash can icon, and the listing goes away. It's a great way to prune your results -- even better would have been if everything trashed brought up something new to look at. That would be a help for those who simply refuse to go past the first page of results. See something you like? Click the heart icon and you can rate the listing. This information is memorized, to help ensure the sites you choose to better in future searches. Unlike KartOO, Ujiko uses results from only one search engine: Yahoo. It also offers many more features I haven't even yet explored, but you can learn more about them here: http://www.ujiko.com/en_htm/. Gary Price also gives a rundown here: http://www.resourceshelf.com/archives/2004_04_01_resourceshelf_archive.html. The only downside? Flash is required. WebCrawler http://www.webcrawler.com Formerly a crawled-based search engine owned by Excite, Webcrawler was acquired by InfoSpace in 2002 and uses the same underlying technology as the other InfoSpace meta search engines, but offers a fast and clean, ad-free interface. ZapMeta http://www.zapmeta.com Provides a variety of ways to sort the results retrieved, plus provides interesting visualization tools and other features. (Review: ZapMeta: A Promising New Meta Search Engine, Feb. 26, 2004) Specialty ChoicesThe metacrawlers listed below let you meta search in specific subject areas.Family Friendly Search http://www.familyfriendlysearch.com Meta search service that queries major kid-friendly search engines. GoFish http://www.gofish.com Meta search service for licensed and commercially available digital media downloads including music, movies, music videos, ringtones, mobile games and PC games, searching over 12 million media files. (Review: GoFish Multimedia Shopping Search: IceRocket Deal & Closer Look, Search Engine Watch Blog, Feb. 4, 2005) Searchy.co.uk http://www.searchy.co.uk Searches 15 U.K. engines. The advanced search form allows you to change the order that results are presented, either by speed or manually to suit your own preferences. Watson for the Macintosh http://www.apple.com/downloads/macosx/internet_utilities/watson.html Watson is a "Swiss Army Knife" with nineteen interfaces to web content and services -- an improvement on Sherlock, with nearly twice as many tools, including Google Searching. All-In-One Search PagesUnlike metacrawlers, all-in-one search pages do not send your query to many search engines at the same time. Instead, they generally list a wide-variety of search engines and allow you to search at your choice without having to go directly to that search engine.Google Versus Yahoo Tool http://www.langreiter.com/exec/yahoo-vs-google.html See visually how results compare on Google versus Yahoo. One Page MultiSearch Engines http://www.bjorgul.com/ Clean interface lets you query major services from one page. Proteus http://www.thrall.org/proteus.html Lets you easily send your search to one of several search engines. It also has links to search engine help pages. Queryster http://www.queryster.com Queryster lets you quickly get results from one of several major search engines, simply by clicking an icon. (Review: A Fun Multi-Search Tool, Feb. 23, 2004) YurNet http://www.yurnet.com Select your search engines from the many choices offered. The results will all appear within one page, side-by-side. It's a great way to compare results, though a bit hard to read with more than two search engines selected. Meta Search ArticlesFor other articles and older reviews, also see the Search Engine Reviews page.Meta Search Engines are Back SearchDay, Dec. 4, 2003 http://www.searchenginewatch.com/searchday/article.php/3109441 It's been a busy year for the major meta search engines, with a number of notable developments that have restored their usefulness as worthy search tools. Meta Search Engines: An Introduction SearchDay, September 16, 2002 http://searchenginewatch.com/searchday/article.php/2160771 This week, SearchDay focuses on the world of meta search engines, looking under the hood at how they work and profiling the major players and their offerings The Big Four Meta Search Engines SearchDay, September 17, 2002 http://searchenginewatch.com/searchday/article.php/2160781 Though there are dozens of useful meta search engines, InfoSpace is the industry gorilla, operating the four arguably best known and most heavily used properties. The Best and Most Popular Meta Search Engines SearchDay, September 18, 2002 http://searchenginewatch.com/searchday/article.php/2160791 Meta search engines look pretty much the same up front, but their approach to presenting results varies widely. Here's a list of Search Engine Watch's pick of the best and most popular metas for searching the web. A Meta Search Engine Roundup SearchDay, September 19, 2002 http://searchenginewatch.com/searchday/article.php/2160801 Completing our roundup of meta search engines, this list focuses on services that are competent and in many cases worthy of a look, but don't meet all of our evaluation criteria. Meta Search Or Meta Ads? The Search Engine Report, June 4, 2001 http://searchenginewatch.com/sereport/article.php/2163821 A review of meta search services by Search Engine Watch shows that some are providing results where more than half of their listings are paid links. A guide to what's paid, what's not and how to get the most from your meta search service. Looking for more articles and reviews of meta search engines? See the Meta Search category of the Search Topics section of Search Engine Watch available to Search Engine Watch members.  This Year's Premier Digital Marketing Event is #CZLSF This Year's Premier Digital Marketing Event is #CZLSFClickZ Live San Francisco (Aug 11-14) will bring together the industry's leading online marketing practitioners to deliver 4 days of educational sessions and training workshops. From Data-Driven Marketing to Social, Mobile, Display, Search and Email, the comprehensive agenda will help you maximize your marketing efforts and ROI. Early Bird Rates available through Friday, July 18. Register & save! -----------------------------------------------------------Welcome to the Internet Search FAQ | ||
| Caught in the Net? Going nowhere on the Information Superhighway? Fear no more. Help is at hand. The Internet Search FAQ is here to help you find what you want - and retain your sanity in the process ...and find hundreds of essential links for searching in Urls for a Rainy Day The main FAQ page is designed to be used by anyone, no matter how much or little you know about searching the Net. Unlike books and pages written by experts, it is based on the kinds of questions that typical users ask: why should I use the Internet? What's the best way to find specific things, specific information, more general information? How can I speed up my searches? Will I get better results if I pay? How reliable is the information I find? | |
While if you're impatient to get started, then go straight to our essential links and start clicking.
We also look at how to find further assistance, and try to guess what changes are on their way (although with the speed the Net changes, they may be happening even as you read).
News and New URLs
The latest on searching and our list of newly discovered resources to help you find your way around whatever subject you want to search on the Net... Click HereFor details of these and other new ways of finding information on the Internet go to our what's new page, updated regularly.
Note: These tools are ranked based on their interface, versatility, and ease of use. The How to Search the Internet provides useful tools to learn about Internet searching. The Best of the Rest provides an eclectic list of other useful resources for a variety of Internet searching needs.
Quick Links to the Top Twelve Search Tools by Category
Click the header for a short description of each tool and a link to the Help menu.

Finding Information on the Internet: A Tutorial
Invisible or Deep Web: What it is, How to find it, and Its inherent ambiguityhttp://www.lib.berkeley.edu/TeachingLib/Guides/Internet/InvisibleWeb.html UC Berkeley - Teaching Library Internet Workshops |
| About This Tutorial | Table of Contents | Contact us |
What is the "Invisible Web", a.k.a. the "Deep Web"?
The "visible web" is what you can find using general web search engines. It's also what you see in almost all subject directories. The "invisible web" is what you cannot find using these types of tools.The first version of this web page was written in 2000, when this topic was new and baffling to many web searchers. Since then, search engines' crawlers and indexing programs have overcome many of the technical barriers that made it impossible for them to find "invisible" web pages.
These types of pages used to be invisible but can now be found in most search engine results:
- Pages in non-HTML formats (pdf, Word, Excel, PowerPoint), now converted into HTML.
- Script-based pages, whose URLs contain a ? or other script coding.
- Pages generated dynamically by other types of database software (e.g., Active Server Pages, Cold Fusion). These can be indexed if there is a stable URL somewhere that search engine crawlers can find.
There are still some hurdles search engine crawlers cannot leap. Here are some examples of material that remains hidden from general search engines:
- The Contents of Searchable Databases. When you search in a library catalog, article database, statistical database, etc., the results are generated "on the fly" in answer to your search. Because the crawler programs cannot type or think, they cannot enter passwords on a login screen or keywords in a search box. Thus, these databases must be searched separately.
- A special case: Google Scholar is part of the public or visible web. It contains citations to journal articles and other publications, with links to publishers or other sources where one can try to access the full text of the items. This is convenient, but results in Google Scholar are only a small fraction of all the scholarly publications that exist online. Much more - including most of the full text - is available through article databases that are part of the invisible web. The UC Berkeley Library subscribes to over 200 of these, accessible to our students, faculty, staff, and on-campus visitors through our Find Articles page.
- Excluded Pages. Search engine companies exclude some types of pages by policy, to avoid cluttering their databases with unwanted content.
- Dynamically generated pages of little value beyond single use. Think of the billions of possible web pages generated by searches for books in library catalogs, public-record databases, etc. Each of these is created in response to a specific need. Search engines do not want all these pages in their web databases, since they generally are not of broad interest.
- Pages deliberately excluded by their owners. A web page creator who does not want his/her page showing up in search engines can insert special "meta tags" that will not display on the screen, but will cause most search engines' crawlers to avoid the page.
How to Find the Invisible Web
Simply think "databases" and keep your eyes open. You can find searchable databases containing invisible web pages in the course of routine searching in most general web directories. Of particular value in academic research are:Use Google and other search engines to locate searchable databases by searching a subject term and the word "database". If the database uses the word database in its own pages, you are likely to find it in Google. The word "database" is also useful in searching a topic in the Yahoo! directory, because they sometimes use the term to describe searchable databases in their listings.
- Examples:
- plane crash database
- languages database
- toxic chemicals database
As part of your web search strategy, spend a little time looking for databases in your field or topic of study or research. The contents of these may not be freely available: libraries and corporations buy the rights for their authorized users to view the contents. If they appear free, it's because you are somehow authorized to search and read the contents (library card holder, company employee, etc.).
The Ambiguity Inherent in the Invisible Web: It is very difficult to predict what sites or kinds of sites or portions of sites will or won't be part of the Invisible Web. There are several factors involved:
- Which sites replicate some of their content in static pages (hybrid of visible and invisible in some combination)?
- Which replicate it all (visible in search engines if you construct a search matching terms in the page)?
- Which databases replicate none of their dynamically generated pages in links and must be searched directly (totally invisible)?
- Search engines can change their policies on what they exclude and include.
Want to learn more about the Invisible Web?
- The Wikipedia "Deep Web" article provides a fairly up-to-date summary, with links to other resources.
| Quick Links |
| Search Engines |Subject Directories | Meta-Search Engines | Invisible Web |

Invisible Web: What it is, Why it exists, How to find it, and Its inherent ambiguity
Copyright © 2012 The Regents of the University of California is licensed
under a Creative Commons Attribution-NonCommercial 3.0 Unported License.
Permissions beyond the scope of this license may be available at
http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/contact.html.
![[ HELP/SEARCH ]](http://www.lib.berkeley.edu/Images/help.gif)
![[ CATALOGS ]](http://www.lib.berkeley.edu/Images/catalogs.gif)
![[ COMMENTS ]](http://www.lib.berkeley.edu/Images/comments.gif)
![[ HOME ]](http://www.lib.berkeley.edu/Images/home.gif)
-----------------------------------------------------------------------------------------------------

Architecture of the World Wide Web, Volume One
W3C Recommendation 15 December 2004
- This version:
- http://www.w3.org/TR/2004/REC-webarch-20041215/
- Latest version:
- http://www.w3.org/TR/webarch/
- Previous version:
- http://www.w3.org/TR/2004/PR-webarch-20041105/
- Editors:
- Ian Jacobs, W3C
- Norman Walsh, Sun Microsystems, Inc.
- Authors:
- See acknowledgments (§8).
See also translations.
Abstract

Status of this document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.This is the 15 December 2004 Recommendation of “Architecture of the World Wide Web, Volume One.” This document has been reviewed by W3C Members, by software developers, and by other W3C groups and interested parties, and is endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the Web.
This document was developed by W3C's Technical Architecture Group (TAG), which, by charter maintains a list of architectural issues. The scope of this document is a useful subset of those issues; it is not intended to address all of them. The TAG intends to address the remaining (and future) issues now that Volume One is published as a W3C Recommendation. A complete history of changes so this document is available. Please send comments on this document to public-webarch-comments@w3.org (public archive of public-webarch-comments). TAG technical discussion takes place on www-tag@w3.org (public archive of www-tag).
This document was produced under the W3C IPR policy of the July 2001 Process Document. The TAG maintains a public list of patent disclosures relevant to this document; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) with respect to this specification should disclose the information in accordance with section 6 of the W3C Patent Policy.
Table of Contents
- 1. Introduction
- 2. Identification
- 3. Interaction
- 4. Data Formats
- 5. General Architecture Principles
- 6. Glossary
- 7. References
- 8. Acknowledgments
List of Principles, Constraints, and Good Practice Notes
The following principles, constraints, and good practice notes are discussed in this document and listed here for convenience. There is also a free-standing summary.- Identification
- Global Identifiers (principle, 2)
- Identify with URIs (practice, 2.1)
- URIs Identify a Single Resource (constraint, 2.2)
- Avoiding URI aliases (practice, 2.3.1)
- Consistent URI usage (practice, 2.3.1)
- Reuse URI schemes (practice, 2.4)
- URI opacity (practice, 2.5)
- Interaction
- Reuse representation formats (practice, 3.2)
- Data-metadata inconsistency (constraint, 3.3)
- Metadata association (practice, 3.3)
- Safe retrieval (principle, 3.4)
- Available representation (practice, 3.5)
- Reference does not imply dereference (principle, 3.5)
- Consistent representation (practice, 3.5.1)
- Data Formats
- Version information (practice, 4.2.1)
- Namespace policy (practice, 4.2.2)
- Extensibility mechanisms (practice, 4.2.3)
- Extensibility conformance (practice, 4.2.3)
- Unknown extensions (practice, 4.2.3)
- Separation of content, presentation, interaction (practice, 4.3)
- Link identification (practice, 4.4)
- Web linking (practice, 4.4)
- Generic URIs (practice, 4.4)
- Hypertext links (practice, 4.4)
- Namespace adoption (practice, 4.5.3)
- Namespace documents (practice, 4.5.4)
- QNames Indistinguishable from URIs (constraint, 4.5.5)
- QName Mapping (practice, 4.5.5)
- XML and "text/*" (practice, 4.5.7)
- XML and character encodings (practice, 4.5.7)
- General Architecture Principles
- Orthogonality (principle, 5.1)
- Error recovery (principle, 5.3)
1. Introduction
The World Wide Web (WWW, or simply Web) is an information space in which the items of interest, referred to as resources, are identified by global identifiers called Uniform Resource Identifiers (URI).Examples such as the following travel scenario are used throughout this document to illustrate typical behavior of Web agents—people or software acting on this information space. A user agent acts on behalf of a user. Software agents include servers, proxies, spiders, browsers, and multimedia players.
- The browser recognizes that what Nadia typed is a URI.
- The browser performs an information retrieval action in accordance with its configured behavior for resources identified via the "http" URI scheme.
- The authority responsible for "weather.example.com" provides information in a response to the retrieval request.
- The browser interprets the response, identified as XHTML by the server, and performs additional retrieval actions for inline graphics and other content as necessary.
- The browser displays the retrieved information, which includes hypertext links to other information. Nadia can follow these hypertext links to retrieve additional information.
Architecture of the World Wide Web, Volume One
-------------------------------------------------------------------------------------------------------------------------------
Developing an Internet Business Plan:

Darkbird18 find this Internet Business Plan by mistake and was glad for it because the Internet Business Plan is real hard to find in one piece! I started looking for the Plan back in 1995 and had a very hard time finding it because no one was trying to develop the Internet Business Plan because they were all too busy trying to get rich! But I keep looking because the foundation is how things are done. A PiTT University student in 1992 Michael Yellin, MBA/MS-MoIS Student, wrote this plan and thank God he put it up online because without it there would be nothing to help new online businesses to go on. Read this plan and you will be ready to setup your online business and make the Internet yours.
Developing an Internet Business Plan*
Introduction:If you are interested in developing a new business on the Internet or expanding your current business onto the global information superhighway, it is important to develop a business plan as part of your preparations. Like a regular business plan, your Internet business plan must give details of the proposed venture, along with expected needs and results (Kuratko and Hodgetts, 1992).
In addition, it must take into account the unique nature of electronic commerce.
Purpose of a Business Plan
A business plan is a proposal for a new venture. It is designed to convince the reader to support the proposed project. If the presenter of the plan is an entrepreneur, the plan's purpose is to raise capital for the project from investors. If the plan is being presented by an employee within a company, then the plan's purpose is to convince internal management to undertake the new project. This planning also has another purpose: to force the entrepreneur to do thorough and effective analysis.Internet Business Issues
Electronic commerce on the Internet is relatively new and poses many unique challenges. First, most people do not know exactly what the Internet is or what it can offer businesses. This is a hurdle that must be overcome in your business plan. Second, resources that are taken for granted in the real world often do not exist or are in formative stages in the on-line world. For example, payment systems, ad page pricing, and market demographic tracking are all in various stages of development on-line. Third, the pace on the Internet is dizzying. Keeping track of the rapidly changing trends, technology, and competitors is crucial to the success of your business.How Much Work is it?
Just like in any endeavor, you would not make substantial investments without careful research and understanding of what you are doing. One example of "Intellichild," a real "dot com business plan," has been posted at http://www.bplans.com/. To my knowledge, this is the only site offering a variety of real business plans free, on line. You can judge the effort required to put together a plan that builds a significant business case.The Ten Sections of an Internet Business Plan
(all but #5, #6, and #10 are required for our course)
- Executive Summary (required): This section must concisely communicate the basics of your entire business plan. Keep in mind that your reader may be unfamiliar with the Internet and its tremendous potential.
- Business Description (required): In this section discuss your firm's product or service along with information about the industry. Because your business plan revolves around the Internet, spend some time explaining it first. Then describe how your product and the Internet fit together or complement each other. As with any business plan, consider your audience. If the readers are technically unsophisticated, make sure you include definitions along with any technological terminology.
- Marketing Plan (required): With the business described, next you must discuss your target market, identify competitors, describe product advertising, explain product pricing, and discuss delivery and payment mechanisms.
- Customers: You must define who your customers are and how many of them exist on the Internet. There are demographic studies by organizations such as The Internet Society and The Internet Group that can help you determine this.
- Competitors: Use Internet search engines to look for known competitors or similar products to yours. Be sure to use several search engines, because each uses different search techniques. After you have identified your competitors, perform a new search every few weeks or months. Companies are continuously joining the Internet. Remember, readers of your business plan will be very interested in how you are going to beat the competition.
- Advertising: Describe how you are going to tell the Internet community about your product or service. Designing beautiful Web pages is only a first step. You must also get the word out about your Web site. Some tips: add your Web address to the databases of search engines such as Lycos and WebCrawler, submit it to What's New at NCSA Mosaic, and add it to the bottom of all of your e-mail messages.
- Pricing: How are you setting prices for your products or services? If your product is intangible information delivered over the Internet, you should try to create some sort of pricing model to justify your prices. You could start by researching what others are charging for similar products.
- Delivery & Payment: How are you going to deliver your product and get paid? E-mail alone is not secure. Consider encryption techniques like PGP, and on-line payment services such as DigiCash.
- Research & Development (required): This is where to get into the technical aspects of your project. Address where the project is now, the R&D efforts that will be required to bring it to completion, and a forecast of how much the project will cost. Since the Internet is continually developing, you should also address continuing plans for R&D.
- Operations & Manufacturing (not required): In this section, discuss the major aspects of the business, including daily operations and physical location. Also, what equipment will your business require? Will you be using your own Web server, or will you be contracting with another company? Who will be your employees -- will you hire Internet knowledgeable staff, or train them in-house? Be sure to include cost information.
- Management (not required): This segment must address who will be running the business and their expertise. Because the business centers around the Internet, be sure to discuss the management team's level of Internet expertise and where they gained it. Also, describe your role in the business.
- Risks (required): In this section, you must define the major risks facing the proposed business. In addition to regular business risks such as downward industry trends, cost overruns, and unexpected entry of competitors, also include risks specific to the Internet. For example, be sure to address the issues of computer viruses, hacker intrusions, and unfavorable new policies or legislation.
- Financial (required): Potential investors will pay close attention to this area, since it is a forecast of profitability. As in a regular business plan, include all pertinent financial statements. Remember to highlight the low expenses associated with operating on the Internet compared to those of other business.
- Timeline (required): In this section, you must lay out the steps it will take to make your proposal a reality. When developing this schedule, it might be helpful to talk to other Internet businesses to get an idea of how long their Internet presences took to establish.
- Bibliography and Appendices (not required): In addition to business references, include some Internet references in case your readers would like to learn more about the Internet as a part of studying your proposal.
Conclusion
You should now have a better idea of what is involved in developing a winning Internet business plan. Remember, the most important points are: addressing the uniqueness of the Internet, explaining its business advantages and potential, and keeping your audience in mind. For further information, the following two sources may be helpful.Sources
Kuratko, Donald F., and Hodgetts, Richard M. Entrepreneurship: A Contemporary Approach, Dryden Press, 1992.Resnick, Rosalind, and Taylor, Dave. The Internet Business Guide: Riding the Information Superhighway to Profit, SAMS Publishing, 1994 * Adapted from a document by Michael Yellin, MBA/MS-MoIS Student
Developing an Internet Business Plan
-----------------------------------------------------------------------------------------------------------------------
WWW Overview
Overview
Internet and Web is not the same thing: Web uses internet to pass over the information.
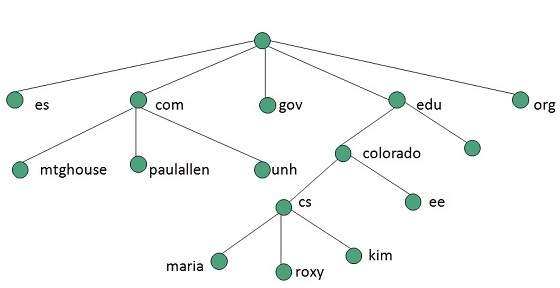
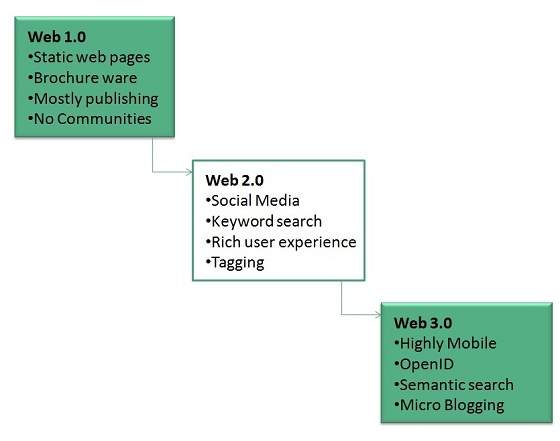
Evolution
WWW Architecture
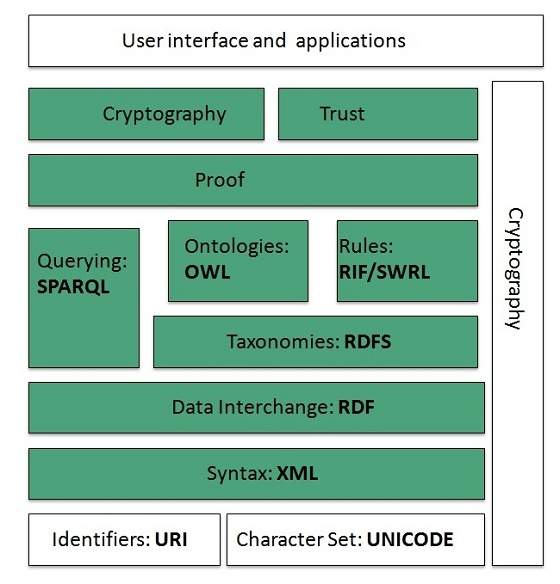
Identifiers and Character Set
Syntax
Data Interchange
Taxonomies
Ontologies
- OWL Lite for taxonomies and simple constraints.
- OWL DL for full description logic support.
- OWL for more syntactic freedom of RDF
Rules
Proof
Cryptography
User Interface and Applications
WWW Operation
- User enters the URL (say, http://www.tutorialspoint.com) of the web page in the address bar of web browser.
- Then browser requests the Domain Name Server for the IP address corresponding to www.tutorialspoint.com.
- After receiving IP address, browser sends the request for web page to the web server using HTTP protocol which specifies the way the browser and web server communicates.
- Then web server receives request using HTTP protocol and checks its search for the requested web page. If found it returns it back to the web browser and close the HTTP connection.
- Now the web browser receives the web page, It interprets it and display the contents of web page in web browser’s window.
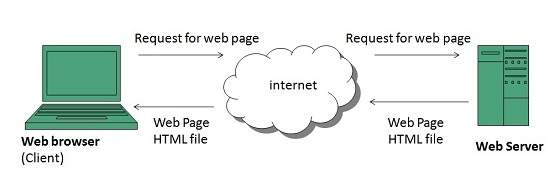
Future
User Interface
Technology
Architecture
References
· "Search Engine History.com". www.searchenginehistory.com. Retrieved 2020-07-02.
· · "Penn State WebAccess Secure Login". webaccess.psu.edu. Retrieved 2020-07-02.
· · Marchiori, Massimo (1997). "The Quest for Correct Information on the Web: Hyper Search Engines". Proceedings of the Sixth International World Wide Web Conference (WWW6). Retrieved 2021-01-10.
· · Brin, Sergey; Page, Larry (1998). "The Anatomy of a Large-Scale Hypertextual Web Search Engine" (PDF). Proceedings of the Seventh International World Wide Web Conference (WWW7). Retrieved 2021-01-10.
· · Harrenstien, K.; White, V. (1982). "RFC 812 - NICNAME/WHOIS". ietf.org. doi:10.17487/RFC0812.
· · "Knowbot programming: System support for mobile agents". cnri.reston.va.us.
· · Deutsch, Peter (September 11, 1990). "[next] An Internet archive server server (was about Lisp)". groups.google.com. Retrieved 2017-12-29.
· · "World-Wide Web Servers". W3.org. Retrieved 2012-05-14.
· · "What's New! February 1994". Home.mcom.com. Retrieved 2012-05-14.
· · "Internet History - Search Engines" (from Search Engine Watch), Universiteit Leiden, Netherlands, September 2001, web: LeidenU-Archie.
· · pcmag. "Archie". pcmag.com. Retrieved 2020-09-20.
· · Alexandra Samuel (21 February 2017). "Meet Alan Emtage, the Black Technologist Who Invented ARCHIE, the First Internet Search Engine". ITHAKA. Retrieved 2020-09-20.
· · loop news barbados. "Alan Emtage- a Barbadian you should know". loopnewsbarbados.com. Retrieved 2020-09-21.
· · Dino Grandoni, Alan Emtage (April 2013). "Alan Emtage: The Man Who Invented The World's First Search Engine (But Didn't Patent It)". huffingtonpost.co.uk. Retrieved 2020-09-21.
· · Oscar Nierstrasz (2 September 1993). "Searchable Catalog of WWW Resources (experimental)".
· · "Archive of NCSA what's new in December 1993 page". 2001-06-20. Archived from the original on 2001-06-20. Retrieved 2012-05-14.
· · "What is first mover?". SearchCIO. TechTarget. September 2005. Retrieved 5 September 2019.
· · Oppitz, Marcus; Tomsu, Peter (2017). Inventing the Cloud Century: How Cloudiness Keeps Changing Our Life, Economy and Technology. Springer. p. 238. ISBN 9783319611617.
· · "Yahoo! Search". Yahoo!. 28 November 1996. Archived from the original on 28 November 1996. Retrieved 5 September 2019.
· · Greenberg, Andy, "The Man Who's Beating Google", Forbes magazine, October 5, 2009
· · Yanhong Li, "Toward a Qualitative Search Engine," IEEE Internet Computing, vol. 2, no. 4, pp. 24–29, July/Aug. 1998, doi:10.1109/4236.707687
· · "About: RankDex", rankdex.com
· · USPTO, "Hypertext Document Retrieval System and Method", US Patent number: 5920859, Inventor: Yanhong Li, Filing date: Feb 5, 1997, Issue date: Jul 6, 1999
· · "Baidu Vs Google: The Twins Of Search Compared". FourWeekMBA. 18 September 2018. Retrieved 16 June 2019.
· · Altucher, James (March 18, 2011). "10 Unusual Things About Google". Forbes. Retrieved 16 June 2019.
· · "Method for node ranking in a linked database". Google Patents. Archived from the original on 15 October 2015. Retrieved 19 October 2015.
· · "Yahoo! And Netscape Ink International Distribution Deal" (PDF). Archived from the original (PDF) on 2013-11-16. Retrieved 2009-08-12.
· · "Browser Deals Push Netscape Stock Up 7.8%". Los Angeles Times. 1 April 1996.
· · Pursel, Bart. Search Engines. Penn State Pressbooks. Retrieved February 20, 2018.
· · Gandal, Neil (2001). "The dynamics of competition in the internet search engine market". International Journal of Industrial Organization. 19 (7): 1103–1117. doi:10.1016/S0167-7187(01)00065-0.
· · "Our History in depth". W3.org. Retrieved 2012-10-31.
· · Jawadekar, Waman S (2011), "8. Knowledge Management: Tools and Technology", Knowledge Management: Text & Cases, New Delhi: Tata McGraw-Hill Education Private Ltd, p. 278, ISBN 978-0-07-07-0086-4, retrieved November 23, 2012
· · Dasgupta, Anirban; Ghosh, Arpita; Kumar, Ravi; Olston, Christopher; Pandey, Sandeep; and Tomkins, Andrew. The Discoverability of the Web. http://www.arpitaghosh.com/papers/discoverability.pdf
· · Jansen, B. J., Spink, A., and Saracevic, T. 2000. Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing & Management. 36(2), 207-227.
· · Chitu, Alex (August 30, 2007). "Easy Way to Find Recent Web Pages". Google Operating System. Retrieved 22 February 2015.
· · "how search engine works?". GFO = 26 June 2018.
· · "What Is Local SEO & Why Local Search Is Important". Search Engine Journal. Retrieved 2020-04-26.
· · "Search Engine Market Share Worldwide". StatCounter GlobalStats. Retrieved March 1, 2022.
· · "Live Internet - Site Statistics". Live Internet. Retrieved 2014-06-04.
· · Arthur, Charles (2014-06-03). "The Chinese technology companies poised to dominate the world". The Guardian. Retrieved 2014-06-04.
· · "How Naver Hurts Companies' Productivity". The Wall Street Journal. 2014-05-21. Retrieved 2014-06-04.
· · "Age of Internet Empires". Oxford Internet Institute. Retrieved 15 August 2019.
· · Waddell, Kaveh (2016-01-19). "Why Google Quit China—and Why It's Heading Back". The Atlantic. Retrieved 2020-04-26.
· · Seznam Takes on Google in the Czech Republic. Doz.
· · Segev, El (2010). Google and the Digital Divide: The Biases of Online Knowledge, Oxford: Chandos Publishing.
· · Vaughan, Liwen; Mike Thelwall (2004). "Search engine coverage bias: evidence and possible causes". Information Processing & Management. 40 (4): 693–707. CiteSeerX 10.1.1.65.5130. doi:10.1016/S0306-4573(03)00063-3. S2CID 18977861.
· · Jansen, B. J. and Rieh, S. (2010) The Seventeen Theoretical Constructs of Information Searching and Information Retrieval. Journal of the American Society for Information Sciences and Technology. 61(8), 1517-1534.
· · Berkman Center for Internet & Society (2002), "Replacement of Google with Alternative Search Systems in China: Documentation and Screen Shots", Harvard Law School.
· · Introna, Lucas; Helen Nissenbaum (2000). "Shaping the Web: Why the Politics of Search Engines Matters". The Information Society. 16 (3): 169–185. CiteSeerX 10.1.1.24.8051. doi:10.1080/01972240050133634. S2CID 2111039.
· · Hillis, Ken; Petit, Michael; Jarrett, Kylie (2012-10-12). Google and the Culture of Search. Routledge. ISBN 9781136933066.
· · Reilly, P. (2008-01-01). Spink, Prof Dr Amanda; Zimmer, Michael (eds.). 'Googling' Terrorists: Are Northern Irish Terrorists Visible on Internet Search Engines?. Information Science and Knowledge Management. Vol. 14. Springer Berlin Heidelberg. pp. 151–175. Bibcode:2008wsis.book..151R. doi:10.1007/978-3-540-75829-7_10. ISBN 978-3-540-75828-0. S2CID 84831583.
· · Hiroko Tabuchi, "How Climate Change Deniers Rise to the Top in Google Searches", The New York Times, Dec. 29, 2017. Retrieved November 14, 2018.
· · Ballatore, A (2015). "Google chemtrails: A methodology to analyze topic representation in search engines". First Monday. 20 (7). doi:10.5210/fm.v20i7.5597.
· · Parramore, Lynn (10 October 2010). "The Filter Bubble". The Atlantic. Retrieved 2011-04-20. Since Dec. 4, 2009, Google has been personalized for everyone. So when I had two friends this spring Google "BP," one of them got a set of links that was about investment opportunities in BP. The other one got information about the oil spill....
· · Weisberg, Jacob (10 June 2011). "Bubble Trouble: Is Web personalization turning us into solipsistic twits?". Slate. Retrieved 2011-08-15.
· · Gross, Doug (May 19, 2011). "What the Internet is hiding from you". CNN. Retrieved 2011-08-15. I had friends Google BP when the oil spill was happening. These are two women who were quite similar in a lot of ways. One got a lot of results about the environmental consequences of what was happening and the spill. The other one just got investment information and nothing about the spill at all.
· · Zhang, Yuan Cao; Séaghdha, Diarmuid Ó; Quercia, Daniele; Jambor, Tamas (February 2012). "Auralist: Introducing Serendipity into Music Recommendation" (PDF). ACM WSDM. doi:10.1145/2124295.2124300. S2CID 2956587.
· · O'Hara, K. (2014-07-01). "In Worship of an Echo". IEEE Internet Computing. 18 (4): 79–83. doi:10.1109/MIC.2014.71. ISSN 1089-7801. S2CID 37860225.
· · "New Islam-approved search engine for Muslims". News.msn.com. Archived from the original on 2013-07-12. Retrieved 2013-07-11.
· · "Jewogle - FAQ".
· · "Halalgoogling: Muslims Get Their Own "sin free" Google; Should Christians Have Christian Google? - Christian Blog". Christian Blog. 2013-07-25.
- · Schwartz, Barry (2012-10-29). "Google: Search Engine Submission Services Can Be Harmful". Search Engine Roundtable. Retrieved 2016-04-04.
Further reading
· Steve Lawrence; C. Lee Giles (1999). "Accessibility of information on the web". Nature. 400 (6740): 107–9. Bibcode:1999Natur.400..107L. doi:10.1038/21987. PMID 10428673. S2CID 4347646.
· Bing Liu (2007), Web Data Mining: Exploring Hyperlinks, Contents and Usage Data. Springer,ISBN 3-540-37881-2
· Bar-Ilan, J. (2004). The use of Web search engines in information science research. ARIST, 38, 231–288.
· Levene, Mark (2005). An Introduction to Search Engines and Web Navigation. Pearson.
· Hock, Randolph (2007). The Extreme Searcher's Handbook.ISBN 978-0-910965-76-7
· Javed Mostafa (February 2005). "Seeking Better Web Searches". Scientific American. 292 (2): 66–73. Bibcode:2005SciAm.292b..66M. doi:10.1038/scientificamerican0205-66.
· Ross, Nancy; Wolfram, Dietmar (2000). "End user searching on the Internet: An analysis of term pair topics submitted to the Excite search engine". Journal of the American Society for Information Science. 51 (10): 949–958. doi:10.1002/1097-4571(2000)51:10<949::AID-ASI70>3.0.CO;2-5.
· Xie, M.; et al. (1998). "Quality dimensions of Internet search engines". Journal of Information Science. 24 (5): 365–372. doi:10.1177/016555159802400509. S2CID 34686531.
· Information Retrieval: Implementing and Evaluating Search Engines. MIT Press. 2010.
Deep Web Search Engines to Explore the Hidden Internet
Feb 11, 2016 · Do you know: There is a vast section of the Internet which is hidden and not accessible through regular search engines and web browsers. This part of the Internet is known as the Deep Web, and it is about 500 times the size of the Web that we know. Deep Web is …
thehackernews.com/2016/02/deep-web-search-engine.html
What Is the Dark Web? How to Access It and What You'll Find
Here’s a quick guide to the deep web, the dark web, and what you’ll find when you get there. What is the dark web? There are basically three parts to the world wide web: surface web, deep web ...
dailydot.com/layer8/what-is-dark-web
The Deep Web you don't know about - money.cnn.com
Mar 10, 2014 · More than 99% of the World Wide Web is hidden beneath the surface as the Deep Web. Here's what's actually there. ... a now-defunct search engine that explored the Deep Web. ... pirated media …
money.cnn.com/2014/03/10/technology/deep-web/index.html
What Is The Difference Between Deep Web, Darknet, And Dark ...
The darknet is a network, and the deep web constitutes the chunk of the World Wide Web that is beyond the reach of the search engines. So, we can decipher dark web as the World Wide Web of the ...
fossbytes.com/difference-deep-web-darknet-dark-web
Oct 18, 2016 · A web crawler (also known as a web spider or web robot) is a program or automated script which browses the World Wide Web in a methodical, automated manner. This process is called Web crawling or ...
sciencedaily.com/terms/web_crawler.htm
Spiders on the Web: Web Crawlers and Search Engines
Jan 25, 2012 · The Dark Side, Web Crawlers can be used for evil as well. ... SEM, SEO, Web Development Tagged With: search engine indexing, search engine optimization, web crawler, web crawler search engine, web crawlers, web root, web search engine, web spiders, world wide web. Speak Your Mind Cancel reply. Name. Email.
interactivesearchmarketing.com/web-crawlers-search-engines
Top Best 50 Free Search Engine Submission Sites List 2019 ...
Top Best 50 Free Search Engine Submission Sites List 2019 January 30, 2019 January 28, 2019 by Bilal Tahir Khan Search Engine Main Part Of Internet Many Search Engine But Google is On Top.Web search engine is a software system that is designed to search for information on the World Wide Web.its work is Different.
alltechabout.com/top-best-50-free-search-engine-submission-sites-lis...
Top 10 Deep Web Search Engines of 2018 - Hacker Combat
Last Update: Feb 26, 2019. Related Dark Web Sources. Cyber Criminals are selling Hacking Tools on the Dark Web. 617 Million Stolen Accounts For ‘Clearance Sale’ In The DarkWeb. Facebook Logins Available on the Dark Web for $2.60. Tor Deep Web Search Engine – How to Download & use Tor Onion Browser Sites Safely (2018 Edition)
hackercombat.com/the-best-10-deep-web-search-engines-of-2017
ISDS 2001 Test Four: Chapter 5 Flashcards | Quizlet
A Web crawler (also called a spider or a Web spider) is a piece of software that systematically browses (crawls through) the World Wide Web for the purpose of finding and fetching Web pages. It starts with a list of "seed" URLs, goes to the pages of those URLs, and then follows each page's hyperlinks, adding them to the search engine's database.
quizlet.com/201174244/isds-2001-test-four-chapter-5-flash-cards
The Deep Web, Dark Web, and what we should know. – Impact ...
The Deep Web, Dark Web, and what we should know. Posted on November 18, 2015 by kwasiterkper Posted in BLOG , digitalsociety — No Comments ↓ Top university researchers say the Web you know like facebook, wikipedia, and news, makes up less than 1% if the entire world wide web.
rampages.us/materials/2015/11/18/the-deep-web-dark-web-and-what-we-shoul...
Dark web: How it is Different From the Deep Web and the ...
What is the Dark Web ? George Paliy Posted on November 16, 2017 June 28, ... In order to crawl a Deep web database, crawler needs to issue appropriate queries to obtain incremental database records, since full crawling would be costly in terms of time and resources. ... For most of us, YouTube is the new TV. The second largest search engine in ...
stopad.io/blog/what-is-the-dark-web-and-how-it-is-different-from-deep-we...
Web Crawling - How Internet Search Engines Work ...
How Internet Search Engines Work. by Curt Franklin Web Crawling. Prev ... When most people talk about Internet search engines, they really mean World Wide Web search engines. Before the Web became the most visible part of the Internet, there were already search engines in place to help people find information on the Net. ... Before a search ...
computer.howstuffworks.com/internet/basics/search-engine1.htm
What is Search Engine Crawler? - brickmarketing.com
A search engine crawler is a program or automated script that browses the World Wide Web in a methodical manner in order to provide up to date data to the particular search engine. While search engine crawlers go by many different names, such as web spiders and automatic indexers, the job of the search engine crawler is still the same.
brickmarketing.com/define-search-engine-crawler.htm
Deep Web Search Engines to Explore the Hidden Internet
Feb 11, 2016 · Some of such Dark Web Search Engines are: Here are some Deep Web Search Engines: These Deep Web search engines talks to the onion service via Tor and relays, resolve the .onion links and then deliver the final output to your regular browser on the ordinary World Wide Web.
thehackernews.com/2016/02/deep-web-search-engine.html
The 13 Best Deep Web Search Engines - The Daily Dot
It’s also probably the oldest web achieve on the whole Internet, and also the most fit example of a “deep web search engine” that’s because it doesn’t list any dark web results, and is solely isolated to rare, hard-to—find, unindexed content which makes it a deep web search engine.
dailydot.com/layer8/best-deep-web-search-engines
Dark web Sites - The Hidden Deep Web Search Engine
The Dark Web search engines are not visible to the public and are not crawled/indexed by any search engine spiders like Google. You might be using the normal search engine (Google, Yahoo, Bing) as a regular basis for searching the terms, In which, you will never get any information from the dark web, which is entirely on the dark side of the deep web.
thedarkwebsites.com
Deep Web Search Engines - Tor Links - Onion Links (2019)
Deep Web Search Engines. The search engines of the deep web work in a structured way. Sim emabrgo the functionality of these browsers in the deep web is to allow the display of text documents. In addition to possible multimedia resources. In addition, it allows you to visit web pages and perform activities on it; that is, link one site with another,...
deepweblinks.net/search-engines
Deep Web Search Engine List [Dark Web] - deepwebsiteslinks
AdCheck for Yourself and Search for Internet Web Search Engines Here!
deepwebsiteslinks.com/deep-web-search-engine-list
6 Best Dark Web Search Engines For Exploring Hidden Internet
The Dark Web, as part of the Deep Web, is defined largely by the fact that search engines can’t index it.Yet, people need to find onion sites in order to use them and many onion sites would be pretty pointless if no one ever visited them. Which brings us to the idea of Dark Web “search engines”.
technadu.com/best-dark-web-search-engines/68922
10 Best hidden (Deep & Dark) Web Search Engines of 2019
The Deep Web refers to all web pages that search engines cannot find, such as user databases, web forums required for registration, webmail pages and pay wall pages. Then there’s the Dark Web or the Dark Net–a special part of the Deep Web hidden.
cybersguards.com/10-best-hidden-deep-dark-web-search-engines-of-2019
Onion.city – a search engine bringing the Dark Web into ...
The Dark Web is reflecting a little more light these days. On Monday I wrote about Memex, DARPA’s Deep Web search engine.Memex is a sophisticated tool set that has been in the hands of a few ...
nakedsecurity.sophos.com/2015/02/18/onion-city-a-search-engine-bringing-...
Dark web Sites | Dark Web Links 2018 | The Hidden Deep Web ...
I already mentioned that Deep/Dark web is a part of the internet that is not indexed by any search engines like Google or Yahoo or Bing. It refers to all the web pages that search engines can’t find such as user databases, registration-required web forums, webmail pages, and pages behind paywalls.
thedarkwebsites.com/page/2
Best Deep Web Search Engines | 01
Another one of the most notorious sites on the Dark Web is the Onion URL Repository. Whether it's one of the best Deep Web search engines, though, is still up for debate. This repository has millions of Dark Web sites, and unlike other search engines, doesn't bar illegal material from its results.
01.media/best-deep-web-search-engines
10 Must-Have Tor / Darknet Search Engines for the Dark Web
The Onion Repository is a rather basic and simple onion search engine link wesbite, but it does boast over one million unique darknet search engine URL results and indexed pages, making it incredibly easy to browse a large selection of tor address Dark Web websites.
drfone.wondershare.com/dark-web/tor-search-engine.html
Deep Web Search Engines - Tor Links - Onion Links (2019)
Deep Web Search Engines. The search engines of the deep web work in a structured way. Sim emabrgo the functionality of these browsers in the deep web is to allow the display of text documents. In addition to possible multimedia resources. In addition, it allows you to visit web pages and perform activities on it; that is, link one site with another,...
deepweblinks.net/search-engines
How to Access the Dark Net and Deep Web Safely - Step by ...
The deep web is often confused with the dark net, also called dark web, black web, and black net. Put simply, the deep web is all of the information stored online that isn’t indexed by search engines.
comparitech.com/blog/vpn-privacy/how-to-access-the-deep-web-and-dark...

- unfiltered search engine with images
- completely unfiltered search engine
- totally unfiltered web search
- search engine that doesn't block anything
- best non filter search engine
- unfiltered search engines that work
- unfiltered dark image search engines
- worldwide search engines unfiltered
{kind=link}
9 comments:
I am professional web researcher. I am available now on fiverr. Data Entry, Web Research, Typing
You are very articulate and explain your ideas and opinions clearly leaving no room for miscommunication.
Please Kindly check My web: buy youtube comments
You are very articulate and explain your ideas and opinions clearly leaving no room for miscommunication.Please Kindly check My web:convert youtube video
You are very articulate and explain your ideas and opinions clearly leaving no room for miscommunication.Please Kindly check My web: video mp3 converter
Очень волшебныеи к тому же поразительно точные интернет гадания для уточнении загадывания своего будущего: это то, с чем вы познакомитесь на нашем портале. Гадание почему является самым приятным и простым вариантом для извлечения важных информаций из эмпирического поля планеты Земля.
You are very articulate and explain your ideas and opinions clearly leaving no room for miscommunication.Please Kindly check My web:"buy tiktok comments''
Значительное число развлекательных программ издается ежегодно. Преимущественно простым путем взять любимую игру считается скачать пк игры бесплатно на русском языке. Знать что к чему в системах ПС игр не особенно легко по причине многочисленного их числа. Перекачав игры с интернета вы получаете невероятный уровень устойчивости. Жулики могут использовать неопытность клиентов и передавать вирусы. Скачка торрента считается простой процедурой, понятной к тому же для неосведомленных посетителей.
В новом магазине покупатель сможет выбрать нужное оснащение на любой бюджет. Проекторы для домашнего кинотеатра цена в Москве, представленные на платформе «Проектор24», – это лучший вариант, какой вы сможете себе представить! Проекторы значатся отличным аналогом плазме, однако предоставляют несколько положительных преимуществ.
Thank you guys for coming by! I hope this information helps you with your online research. Darkbird18
Post a Comment